요구사항
repartition
- code 를 참조하여 날짜 별로 진행(virtualenv operator + PDM 으로 만든 패키지)
- /home//data/movie/repartition/
$ git clone https://github.com/samdulshopmovie/movie_data.git
$ cd movie_data/data/extract
$ cp -rf load_dt=20150101 ~/tmp/sparkdata
df = pd.read_parquet('~/tmp/sparkdata')
df.to_parquet('~/tmp/sparkpartition', partition_cols=['load_dt','multiMovieYn', 'repNationCd'])join_df
- spark sql 을 활용(어제 작성한 제플린 코드) 하여 movie_join_df.py 을 $AIRFLOW_HOME/py 밑에 생성
- spark-submit 을 사용 airflow bash operator 를 이용
- 아래 pyspark 코드를 활용하여 HIVE 형식에 맞는 파티션 생성
df.write.partitionBy("load_dt", "multiMovieYn", "repNationCd").parquet("/home/<ID>/data/movie/hive/")agg
- sparksql 을 사용하여 일별 독립영화 여부, 해외영화 여부에 대하여 각각 합을 구하기(누적은 제외 일별관객수, 수익)
- 위에서 구한 SUM 데이터를 "/home//data/movie/sum-multi", "/home//data/movie/sum-nation" 에 날짜를 파티션 하여 저장
제플린 대시보드 만들기
- 위에서 저장한 "/home//data/movie/sum-multi", "/home//data/movie/sum-nation" 데이터를 load 하여 차트 만들기
1. branch.op, rm_dir (DAG)

Airflow에서 branch.op를 써서 멱등성을 보장하도록했다.
branch.op는 해당날짜의 reapartiton 파일이 존재하면 삭제하고, 없으면 re.partition으로 보낸다.
def branch_op(ds_nodash):
import os
home_dir = os.path.expanduser("~")
path = f"{home_dir}/data/movie/repartition/load_dt={ds_nodash}"
if os.path.exists(path):
return rm_dir.task_id
else:
return re_partition.task_id
print("branch fin!") branch_op = BranchPythonOperator(task_id="branch.op", python_callable=branch_op)
rm_dir = BashOperator(
task_id='rm.dir',
bash_command='rm -rf ~/data/movie/repartition/load_dt={{ds_nodash}}'
)2. re_partition
re.py
import pandas as pd
def re_partition(load_dt):
base_path='~/movie_data/data/extract'
save_path='~/data/movie/repartition'
df = pd.read_parquet(f'{base_path}/load_dt={load_dt}')
df['load_dt'] = load_dt
df.to_parquet(save_path, partition_cols=['load_dt','multiMovieYn', 'repNationCd'])
강사님의 코드는 코드 내에 멱등성을 보장하는 과정을 거쳐서 좀 더 복잡했다.
https://github.com/dMario24/spark_flow/tree/0.3.1/pyspark (강사님 코드)
DAG
def re_partition(ds_nodash):
from spark_flow.re import re_partition
re_partition(ds_nodash) re_partition = PythonVirtualenvOperator(
task_id='re.partition',
python_callable=re_partition,
requirements=['git+https://github.com/oddsummer56/spark_flow.git@0.1.0/simple'], #re_partiton 코드
system_site_packages=False,
#trigger_rule="all_done",
#venv_cache_path="/home/kim1/tmp2/airflow_venv/get_data"
)3. df_join
movie_df_join.py
from pyspark.sql import SparkSession
import sys
spark = SparkSession.builder.appName("joinDF").getOrCreate()
load_dt = sys.argv[1]
df=spark.read.parquet(f"/home/oddsummer/data/movie/repartition/load_dt={load_dt}")
df.createOrReplaceTempView("movie")
# multiMovieYn이 NULL인 데이터를 필터링하여 DataFrame으로 생성
df_m=spark.sql(f"""
SELECT
movieCd, -- 영화의 대표코드
movieNm,
salesAmt, -- 매출액
audiCnt, -- 관객수
showCnt, --- 상영횟수
multiMovieYn, -- 다양성 영화/상업영화를 구분지어 조회할 수 있습니다. “Y” : 다양성 영화 “N”
repNationCd, -- 한국/외국 영화별로 조회할 수 있습니다. “K: : 한국영화 “F” : 외 국영화
'{load_dt}' AS load_DT
FROM movie
WHERE multiMovieYn IS NULL""")
df_m.createOrReplaceTempView("multi_null")
# repNationCd가 NULL인 데이터를 필터링하여 DataFrame으로 생성
df_n=spark.sql(f"""
SELECT
movieCd, -- 영화의 대표코드
movieNm,
salesAmt, -- 매출액
audiCnt, -- 관객수
showCnt, --- 사영횟수
multiMovieYn, -- 다양성 영화/상업영화를 구분지어 조회할 수 있습니다. “Y” : 다양성 영화 “N”
repNationCd, -- 한국/외국 영화별로 조회할 수 있습니다. “K: : 한국영화 “F” : 외>국영화
'{load_dt}' AS load_DT
FROM movie
WHERE repNationCd IS NULL
""")
df_n.createOrReplaceTempView("nation_null")
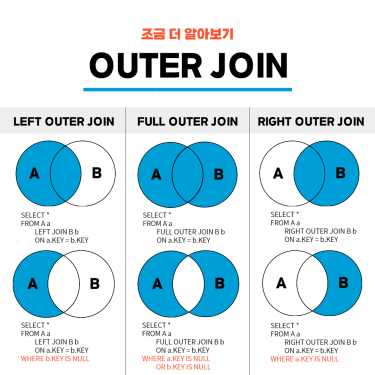
# 두 개의 TempView (multi_null, nation_null)를 FULL OUTER JOIN으로 병합
df_join=spark.sql(f"""
SELECT
COALESCE(m.movieCd, n.movieCd) AS movieCd,
COALESCE(m.movieNm, n.movieNm) AS movieNm,
COALESCE(m.salesAmt, n.salesAmt) AS salesAmt,
COALESCE(m.audiCnt, n.audiCnt) AS audiCnt,
COALESCE(m.showCnt, n.showCnt) AS showCnt,
COALESCE(m.multiMovieYn, n.multiMovieYn) AS multiMovieYn,
COALESCE(m.repNationCd, n.repNationCd) AS repNationCd,
'{load_dt}' AS load_DT
FROM multi_null m FULL OUTER JOIN nation_null n
ON m.movieCd = n.movieCd""")
df_join.createOrReplaceTempView("join")
df_join.show(30)
df_join.write.mode('append').partitionBy("load_dt", "multiMovieYn", "repNationCd").parquet("/home/oddsummer/data/movie/hive")
spark.stop()
과정은 다음과 같다.
1. repartiton 데이터 불러와서 movie 테이블로 저장
2. multiMovieYn 이 NULL인 데이터 필터링
3. repNationCd 가 NULL인 데이터 필터링
- COALESCE 함수는 두 테이블 중 어느 하나에만 존재하는 경우에도 NULL이 아닌 값을 반환하도록 한다. 둘 다 존재하는 경우 처음 값 반환.
4. Full Outer Join 으로 데이터 병합
5. 결과 확인 및 parquet 파일로 저장
Apache Spark를 사용하여 load_dt 에 대한 영화 데이터를 읽고, multiMovieYn 과 repNationCd 을 기준으로 데이터를 분리한 후, 해당 데이터를 병합하여 결과를 저장하는 작업을 수행한다.
multi_null과 nation_null 두 테이블에서 영화 코드를 기준으로 두 개의 데이터프레임을 결합하여 어느 한쪽에만 존재하는 데이터도 포함시켜 출력한다.

참고 공식가이드 : https://spark.apache.org/docs/latest/quick-start.html#self-contained-applications
DAG
join_df = BashOperator(
task_id='join.df',
bash_command="""
SPARK_HOME=~/app/spark-3.5.1-bin-hadoop3
AIRFLOW_HOME=~/airflow_pyspark
$SPARK_HOME/bin/spark-submit $AIRFLOW_HOME/py/movie_join_df.py {{ds_nodash}}
"""
)4. agg_df
movie_agg_df.py
from pyspark.sql import SparkSession
import sys
spark = SparkSession.builder.appName("aggDF").getOrCreate()
df=spark.read.parquet(f"/home/oddsummer/data/movie/hive")
df.createOrReplaceTempView("movie")
#국내/해외영화별 매출액, 관객수 집계
df1= spark.sql(f"""
SELECT load_dt as load_dt,
repNationCd,
sum(salesAmt) as salesAmt,
sum(audiCnt) as audiCnt,
sum(showCnt) as showCnt
FROM movie
GROUP BY load_dt, repNationCd
ORDER BY load_dt
"""
)
df1.createOrReplaceTempView("nation")
#독립/상업영화별 매출액, 관객수 집계
df2 = spark.sql(f"""
SELECT load_dt as load_dt,
multiMovieYn,
sum(salesAmt) as salesAmt,
sum(audiCnt) as audiCnt,
sum(showCnt) as showCnt
FROM movie
GROUP BY load_dt, multiMovieYn
ORDER BY load_dt
"""
)
df2.createOrReplaceTempView("multi")
df1.write.mode('overwrite').partitionBy("load_dt", "repNationCd").parquet("/home/oddsummer/data/movie/sum_nation")
df2.write.mode('overwrite').partitionBy("load_dt", "multiMovieYn").parquet("/home/oddsummer/data/movie/sum_multi")
spark.stop()
Apache Spark를 사용하여 영화 데이터를 분석하고, 두 가지 기준(국내/해외 영화 및 독립/상업 영화)으로 매출액, 관객수, 상영횟수를 집계한 후, 결과를 저장하는 작업을 수행.
DAG
agg_df = BashOperator(
task_id='agg.df',
bash_command="""
SPARK_HOME=~/app/spark-3.5.1-bin-hadoop3
AIRFLOW_HOME=~/airflow_pyspark
$SPARK_HOME/bin/spark-submit $AIRFLOW_HOME/py/movie_agg_df.py
"""
)전체 DAG 코드
from datetime import datetime, timedelta
from textwrap import dedent
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.bash import BashOperator
from airflow.operators.empty import EmptyOperator
from airflow.operators.python import (
PythonOperator, PythonVirtualenvOperator, BranchPythonOperator
)
with DAG(
'pyspark_movie',
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
'depends_on_past': False,
'retries': 2,
'retry_delay': timedelta(seconds=3),
'max_active_tasks': 3,
'max_active_runs': 1,
},
description='pyspark',
#schedule=timedelta(days=1),
schedule="0 5 * * *",
start_date=datetime(2017, 1, 1),
end_date=datetime(2018, 1, 1),
catchup=True,
tags=['pyspark', 'movie'],
) as dag:
def re_partition(ds_nodash):
from spark_flow.re import re_partition
re_partition(ds_nodash)
def branch_op(ds_nodash):
import os
home_dir = os.path.expanduser("~")
path = f"{home_dir}/data/movie/repartition/load_dt={ds_nodash}"
if os.path.exists(path):
return rm_dir.task_id
else:
return re_partition.task_id
print("branch fin!")
rm_dir = BashOperator(
task_id='rm.dir',
bash_command='rm -rf ~/data/movie/repartition/load_dt={{ds_nodash}}'
)
re_partition = PythonVirtualenvOperator(
task_id='re.partition',
python_callable=re_partition,
requirements=['git+https://github.com/oddsummer56/spark_flow.git@0.1.0/simple'],
system_site_packages=False,
#trigger_rule="all_done",
#venv_cache_path="/home/kim1/tmp2/airflow_venv/get_data"
)
join_df = BashOperator(
task_id='join.df',
bash_command="""
SPARK_HOME=~/app/spark-3.5.1-bin-hadoop3
AIRFLOW_HOME=~/airflow_pyspark
$SPARK_HOME/bin/spark-submit $AIRFLOW_HOME/py/movie_join_df.py {{ds_nodash}}
"""
)
agg_df = BashOperator(
task_id='agg.df',
bash_command="""
SPARK_HOME=~/app/spark-3.5.1-bin-hadoop3
AIRFLOW_HOME=~/airflow_pyspark
$SPARK_HOME/bin/spark-submit $AIRFLOW_HOME/py/movie_agg_df.py
"""
)
task_start = EmptyOperator(task_id='start')
task_end = EmptyOperator(task_id='end', trigger_rule="all_done")
branch_op = BranchPythonOperator(task_id="branch.op", python_callable=branch_op)
task_start >> branch_op >> [re_partition, rm_dir]
rm_dir >> re_partition
re_partition >> join_df >> agg_df >> task_end'Data Engineering > 실습' 카테고리의 다른 글
| fastapi + movie api (2) | 2024.08.13 |
|---|---|
| 영화진흥위원회 API (pytest 실습) (0) | 2024.08.01 |
| argparse 를 이용한 히스토리 cli 고도화 (0) | 2024.07.29 |
| DB 파티셔닝 (Partitioning) (0) | 2024.07.29 |
| Parquet 파일 형식 (0) | 2024.07.26 |