1. JSON 파일 불러오기
%spark.pyspark
import os
input_path = os.path.expanduser('~/data/movbotdata/movieList.json')
jdf = spark.read.option("multiline", "true").json(input_path)
#jdf = spark.read.option("multiline","true").json('/home/odsummer/data/movbotdata/movieList.json')
json파일 안에 데이터 형식 단일이 아닌 여러줄로 구성되어 있는 경우, multiline 값을 true로 주는 옵션을 줘야한다.
2. JSON 파일 스키마 확인
%spark.pyspark
jdf.printSchema()
root
|-- companys: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- companyCd: string (nullable = true)
| | |-- companyNm: string (nullable = true)
|-- directors: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- peopleNm: string (nullable = true)
|-- genreAlt: string (nullable = true)
|-- movieCd: string (nullable = true)
|-- movieNm: string (nullable = true)
|-- movieNmEn: string (nullable = true)
|-- nationAlt: string (nullable = true)
|-- openDt: string (nullable = true)
|-- prdtStatNm: string (nullable = true)
|-- prdtYear: string (nullable = true)
|-- repGenreNm: string (nullable = true)
|-- repNationNm: string (nullable = true)
|-- typeNm: string (nullable = true)
companys와 directors는 array타입이기 때문에 행과 열로 이루어진 테이블로 만들 때 분리하거나 필요한 것만
3. 중첩된 필드나 배열 안에 있는 필드를 최상위 수준의 필드로 펼치고, 리스트나 중첩된 요소를 개별 행으로 펼치기
%spark.pyspark
from pyspark.sql import DataFrame
from pyspark.sql.functions import col, explode_outer
from pyspark.sql.types import StructType, ArrayType
def flatten_schema(df: DataFrame) -> DataFrame:
"""
주어진 DataFrame에서 중첩된 구조체(StructType) 필드를 모두 최상위 필드로 평탄화합니다.
"""
while True:
has_struct = False # StructType이 존재하는지 여부를 확인하는 플래그
for field in df.schema.fields:
# StructType 필드인지 확인
if isinstance(field.dataType, StructType):
has_struct = True # StructType 필드가 있음을 표시
# 모든 컬럼을 선택하고, 중첩된 필드를 최상위 레벨 컬럼으로 추가
expanded_cols = [
col(f"{field.name}.{nested_field.name}").alias(f"{field.name}_{nested_field.name}")
for nested_field in field.dataType.fields
]
# 기존 컬럼에 새로 평탄화된 컬럼들을 추가하고 원래의 StructType 컬럼은 삭제
df = df.select("*", *expanded_cols).drop(field.name)
break # 스키마가 변경되었으므로 다시 처음부터 확인하기 위해 루프를 종료
# ArrayType이면서, 그 내부가 StructType인 경우 먼저 배열을 풀어낸 후 처리
elif isinstance(field.dataType, ArrayType) and isinstance(field.dataType.elementType, StructType):
has_struct = True # 처리할 StructType 필드가 있음을 표시
# 배열을 풀어내기 위해 explode_outer 적용
df = df.withColumn(field.name, explode_outer(field.name))
break # 스키마가 변경되었으므로 다시 처음부터 확인하기 위해 루프를 종료
# 더 이상 StructType 필드가 없으면 반복을 종료
if not has_struct:
break
return df
# 사용 예시: jdf가 입력 DataFrame이라고 가정
flat_df = flatten_schema(jdf)
- 반복 루프 설정 (while True):
- DataFrame에 더 이상 StructType이나 ArrayType이 남아있지 않을 때까지 반복.
- StructType 필드 탐색:
- df.schema.fields를 통해 DataFrame의 모든 필드를 순회.
- 만약 StructType 필드가 발견되면, 그 안의 각 하위 필드를 최상위 레벨로 가져오기 위해 expanded_cols 리스트를 만든다. 예를 들어, companys라는 StructType 필드가 있으면, 그 내부의 companyCd, companyNm 같은 필드를 최상위 레벨로 옮긴다.
- df.select("*", *expanded_cols).drop(field.name)를 통해 기존의 모든 컬럼에 더해 새로 평탄화된 컬럼들을 추가하고, 원래의 StructType 필드는 삭제.
- 스키마가 변경되었으므로 루프를 종료하고 다시 처음부터 확인.
- ArrayType 필드 탐색 및 처리:
- 만약 ArrayType 필드가 발견되었고, 그 내부가 StructType으로 구성되어 있다면, 먼저 이 배열을 explode_outer를 사용해 풀어낸다.
- explode_outer는 배열 내의 각 요소를 개별 행으로 확장하여 DataFrame의 구조를 평탄화.
- 이 경우에도 스키마가 변경되므로 루프를 종료하고 다시 처음부터 확인.
- 루프 종료 조건:
- 더 이상 StructType 필드가 남아 있지 않으면, has_struct 플래그가 False로 설정되어 루프를 종료.
- 최종 결과 반환:
- 모든 중첩된 구조체 필드가 최상위로 평탄화된 DataFrame이 반환.
위 코드를 실행하면 다음과 같이 중첩된 구조들이 최상위 레벨로 평탄화 되고


리스트나 반복 가능한 요소들을 개별 행으로 펼쳐졌음을 알 수 있다.


프로세스를 요약하자면 다음과 같다.
- 데이터프레임의 스키마를 반복적으로 확인하면서, StructType 또는 ArrayType을 찾는다.
- ArrayType은 배열을 나타내며, 그 내부에 StructType이 존재하는 경우 배열을 먼저 풀어내고(explode_outer) 그 이후에 StructType을 평탄화한다.
- StructType은 중첩된 구조체 필드를 나타내며, 이 코드에서는 그러한 필드가 존재할 경우 이를 평탄화하여 최상위 필드로 변환하고, 원래의 중첩된 구조체 필드를 제거한다.
- 이 과정을 더 이상 평탄화할 중첩된 구조체나 배열이 없을 때까지 반복한다.
4. JSON 파일로 저장하기
%spark.pyspark
import json
import os
# 데이터프레임을 로컬로 수집
data = <저장하려는 df>.collect()
# JSON 형식으로 변환하여 UTF-8로 저장
output_path = os.path.expanduser('~/data/movbotdata/<파일명>.json')
with open(output_path, 'w', encoding='utf-8') as f:
json.dump([row.asDict() for row in data], f, ensure_ascii=False, indent=4)+) explode vs explode_outer
explode는 빈 배열과 null 값을을 가진 행을 제거하지만, explode_outer는 null값을 유지하거나 빈 배열을 null로 변환하여 해당 행을 출력한다.
- 중복 데이터: explode와 explode_outer는 모두 중복된 값을 그대로 확장하여 개별 행으로 나눈다.
- 중첩된 리스트: 두 함수 모두 중첩된 리스트를 평탄화하지 않고, 리스트 형태로 남긴다. 중첩된 리스트를 처리하려면 추가적인 평탄화 작업이 필요하다.
- 빈 배열: explode는 빈 배열을 가진 행을 제거한다. explode_outer는 빈 배열을 null로 변환하고, 해당 행을 유지한다.
- null 값: explode는 null 값을 가진 행을 제거하지만, explode_outer는 null 값을 유지하면서 해당 행을 출력한다.
초기 edf 데이터프레임
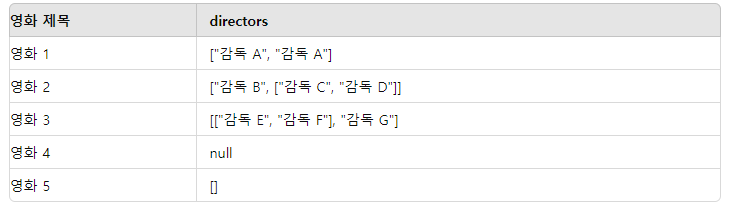
explode 적용 후 데이터프레임
edf_explode = edf.withColumn("director", explode("directors"))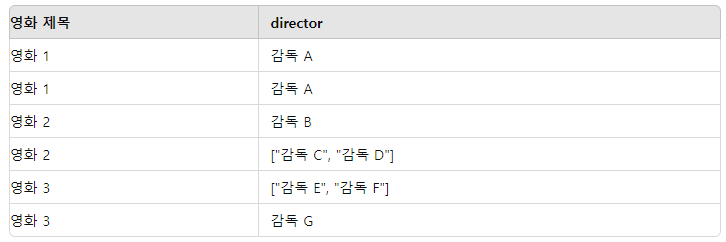
explode_outer 적용 후 데이터프레임
edf_explode_outer = edf.withColumn("director", explode_outer("directors"))

'Data Engineering > Spark' 카테고리의 다른 글
| [SPARK] 분산 처리 시스템, 클러스터 (0) | 2024.08.17 |
|---|---|
| [SPARK] spark-submit option (total-executor-cores , num-executors) (0) | 2024.08.16 |
| spark, 분산처리, 배치처리 개념 / spark, zeppline, java 설치 (0) | 2024.08.14 |